
.png)
AI Evaluation
Evaluate your Agent's responses across edge cases, Tool calls, and guardrail compliance. Find gaps, fix them, retest, and deploy when scores prove you're ready.





The system analyzes your Knowledge Base, prompt instructions, and connected Tools to generate comprehensive test question sets. It creates queries about your policies, edge cases around your products, scenarios that require Tool calls, and questions designed to test guardrail adherence. You get dozens or hundreds of relevant test questions without manually brainstorming every possible customer interaction.
Create multiple test groups for a single AI Agent, each with different question sets and validation goals. A comprehensive group with questions covering all scenarios. A focused group testing only refund policy edge cases. A compliance group for regulatory requirements. Add questions to existing groups as new scenarios emerge, upload your own from past support tickets, edge cases from planning sessions, or compliance-critical queries that must be answered exactly right.
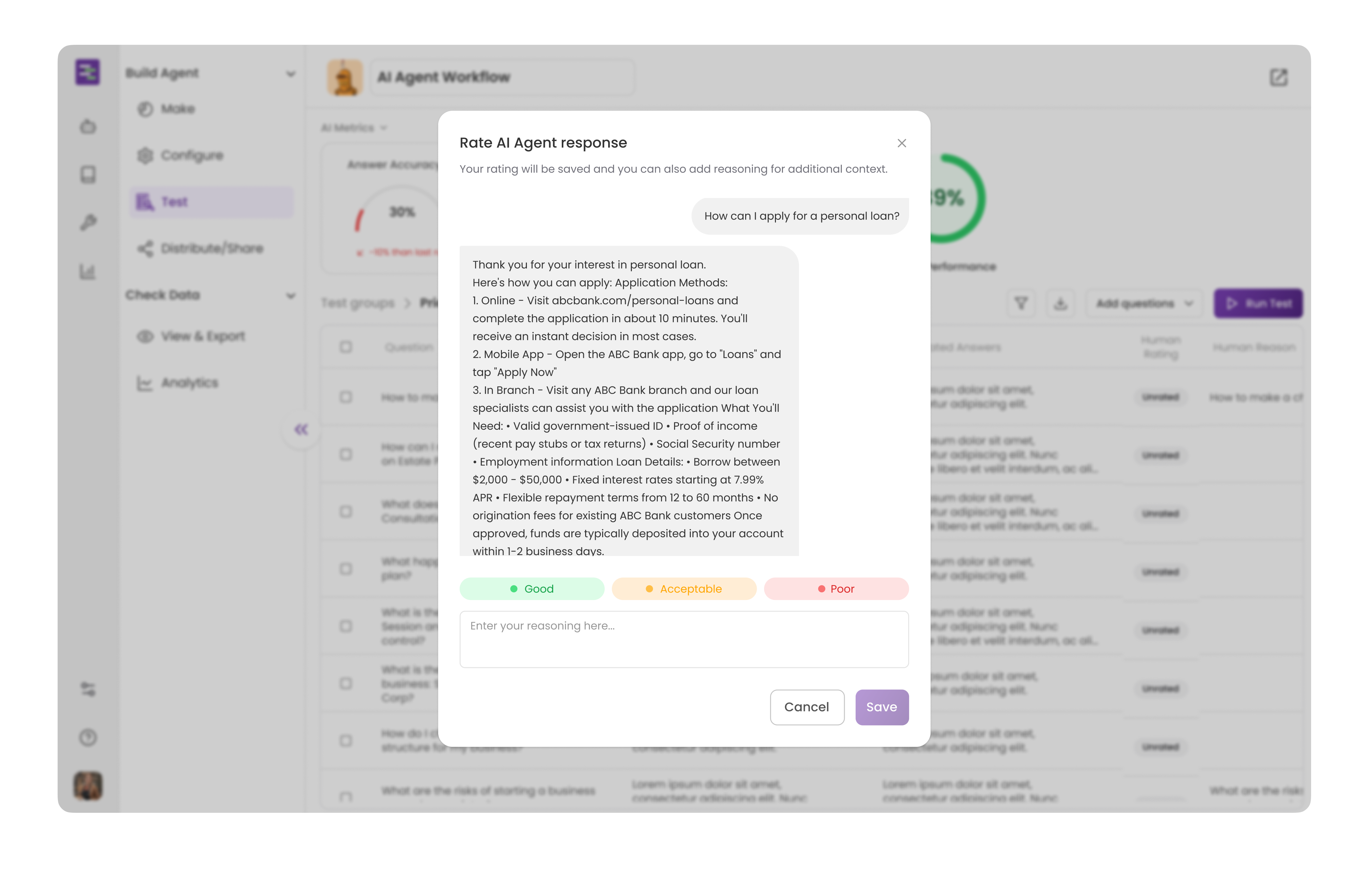
Each test question produces an Agent response scored across three critical dimensions. Answer Accuracy measures whether the response is factually correct based on available information, right refund timelines, correct pricing, and accurate product specifications. Context Relevance evaluates whether the Agent understood what was actually being asked and retrieved the right information. A question about returns shouldn't pull shipping policy documentation. Answer Faithfulness checks whether the response stays true to the retrieved Knowledge Base content without fabrication. The Agent should cite what exists in documentation, not invent details or speculate beyond available information.
You can rate each answer based on your understanding as well. The system provides automated scoring, but you also have full control to add your own rating (good, average, or poor) for any answer. When rating an answer, you can provide detailed reasoning explaining your assessment. The overall rating and performance score dynamically reflect both the automated metrics and your human ratings, ensuring the evaluation truly represents real-world quality. This complete breakdown shows exactly where your Agent excels and where it needs improvement across all dimensions.
.png)
The old process meant typing variations of questions manually, creating random edge cases, collating questions from scattered data sources, and testing each answer one by one with no systematic tracking. Now you fix identified gaps, add missing documentation, refine prompt instructions, adjust retrieval settings, and rerun the same test batch. Score improvements are quantified after each run. For instance, you can identify that the refund policy questions jumped from 60% good answers to 95% after adding two Knowledge Base documents.
Most teams deploy AI Agents on hope and intuition, then discover problems when real customers are already frustrated. Evaluation turns deployment into a data-driven decision. You set quality thresholds based on your risk tolerance. Customer-facing financial advice might require 95% very good scores. Internal IT support might deploy at 80% good or better. When your test results hit your threshold, you deploy knowing your Agent performs consistently across the scenarios you care about. No surprises in production.
Helps citizens report municipal service issues like potholes, graffiti, and missed trash collection by creating official work orders for city crews. It also provides status updates and general information about city services.

Helps employees find guidance on IT issues and provides troubleshooting steps. If the issue is unresolved, it raises a ticket for IT support.

Sits at your hospital entrance to help patients find the right specialist and room number based on symptoms, providing step-by-step directions and reducing front desk inquiries.

Educates on plans, services, pricing, and perks, then collects user data and takes the user to a placeholder payment gateway once they have chosen a service.

Collects customer information and problem details to provide accurate cost estimates for plumbing, electrical, and HVAC services, then creates work orders for expert callbacks.

Educates customers about credit card options through targeted questions about their credit situation and spending habits, then recommends the best-fit product with detailed reward calculations and application guidance.

















Connect with tools where your data lies



























Privacy & Security
At Tars, we take privacy and security very seriously. We are compliant with GDPR, ISO, SOC 2, and HIPAA.





Email - sales@hellotars.com




.png)
%201.png)
%201.png)



